
Guide to Fetch


But always verify the content it provides.
The Challenge
Seeding is a clumsy process. Source articles have very different structures, embed advertisements and other distractions, including at times complex HTML that screws up the formatting. Time must be spent copying & pasting contents and then cleaning up the resultant mess in NT. On top of that, the process of downloading an appropriate image so that it can be uploaded and attached to the article is annoying. Finally, it is not always easy or possible to attribute the seed properly to the original author.
Fetch
The Fetch functionality uses a collection of heuristic techniques to acquire as much good content while ignoring as much bad as possible. It aggressively pours through the HTML of seed articles to get:
Title : This is almost always easily found in an article so Fetch will typically provide the correct title
Quote or Summary : If supplied by the author, Fetch will place the summary in the Quote field
Author (and site) : Surprisingly, the author is often omitted or embedded in the actual content of the article. Fetch uses a sophisticated method to determine the author. But since this must be extracted from unstructured English, the author will not always be correct. Also, sometimes articles provide a meta-data field for author but then put in the wrong information. Author is one key field a seeder needs to scrutinize.
Content : Ideally this is the core content of the seed. This is often buried as a minority of content in an otherwise complex mess of HTML and related instructions. Further, publishers often embed advertisement and teasers among the content (before, within and after). Although Fetch tries to weed out the bad content, the seeder will often need to do more editorial work.
Designated Image : Most every seed has a designated image. This is the image deemed by the author to go with the seeded article. Fetch can find this almost every time, but there are occasions when the seeded article has no image, states the wrong URL for the image, etc. In these cases, the seeder must manually provide an image (but Fetch can help there too, see: FETCH IMAGE).
Embedded Media : Optionally, the seeder can ask Fetch to include appropriate embedded images and videos. These are graphical media sprinkled throughout the content of the article. This is not something the seeder would typically do, but the option is available.
Fetch appears to the user as one or two buttons on the upper right corner of your Create Article or Update Article forms. The principle button is labeled FETCH SEED . This is the workhorse that accepts a URL from the user and then goes to the web to attempt to acquire that which is needed for an NT seed. The FETCH SEED button appears when you are trying to create a Discussion or a Group Discussion . It does not appear when creating a Blog because blogs are always original work (never seeded).
The other button is FETCH IMAGE . This button appears when you create or update any type of article. It gives the user the option to enter a URL instead of downloading a file to one's local machine and then uploading into NT. FETCH IMAGE does all that work for you.
Note : you will not usually use FETCH IMAGE since FETCH SEED frequently brings in the author-designated image for you.
Disclaimer
Fetch is atypical automation; it works on imperfect data and the results will vary per article and per site. Fetch contends with a very messy world of inconsistent standards, human error and wildly different formats and styles. It must grab raw code from an arbitrary target website (what Browsers process before presenting a nice view to the user) and extract only that which is needed for an NT seed. To make sense of this content, Fetch contains a complex set of inferencing tools designed to cleanse and surgically extract desired content. While it is usually not possible for Fetch to construct a seed as well as a human seeder (Fetch operates at the server level and thus does not have the benefit of a sophisticated browser), it does handle a lot of the grunt work and ideally leaves the seeder with minor cleanup work.
Sometimes Fetch delivers perfection, sometimes the results are ugly. Expect to find cases where Fetch ed content contains embedded advertisement, and sometimes complete junk (like portions of script code). These items are usually a result of poorly encoded HTML content that lacks sufficient information for Fetch (and its supporting third party tools) to detect and remove. Basically, if an author / site embeds content in the middle of an article and provides no markers to distinguish it from the true content of the article, there is nothing Fetch can do. To Fetch, it all looks like article content.
In contrast to excess unwanted content, Fetch cannot always get necessary information from a site. Twitter delivers almost entirely junk so Fetch will typically at best get the tweet itself. Some sites (e.g. Bloomberg) prevent bots ( Fetch is effectively a bot ) from acquiring their content. Some sites forbid access to their images (access denied). Other sites use dynamic content which appear only as a result of the browser interacting with the server; Fetch cannot even see this content (an example of this is a picture gallery). When Fetch is not able to provide good content, the seeder should create the seed using the old manual approach (copy & paste). However, even here, the FETCH IMAGE function will be available to facilitate acquiring a suitable image directly from the web (vs. download / upload).
Usage
When you click on the FETCH SEED button you will see the following dialog box:
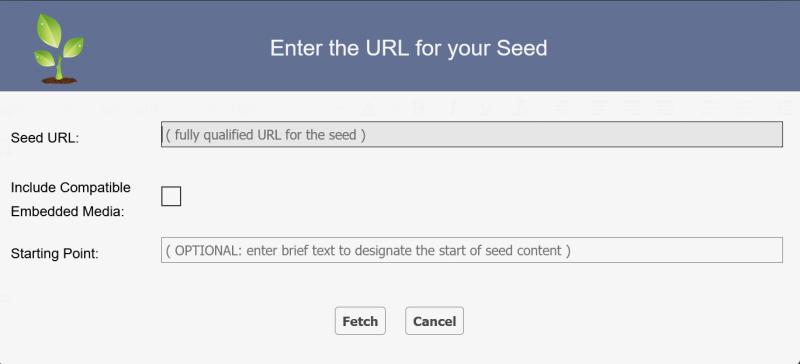
Seed URL : is the URL you wish Fetch to access. Paste in your fully qualified URL.
Include Compatible Embedded Media : checkbox is normally unchecked. Thus Fetch will normally not include pictures and videos. If you would like pictures and videos (at least those that are valid for NewsTalkers) then check this box.
Starting Point : is rarely used. Its purpose is to give Fetch your desired starting point in the article. This will be used if the article has a bunch of junk content upfront and Fetch has no way to distinguish it from good (MSN likes to do this). In this case, you would copy & paste (this must be exact) a unique portion of the starting sentence in the article. Fetch will scan the content looking for this exact match and, if found, take that as the beginning of the article (and will throw away all content that precedes it).
Once you have entered in your data (typically just the URL), press the FETCH button to automatically populate your seeded article.
Summary
Fetch seeks to make seeding easier. It will not eliminate all the work but in most cases greatly streamlines the process. If Fetch does not work well for a site, the legacy functionality (the copy & paste you do today) for seeds is still in place.
One should use Fetch as a support tool and always verify the content it provides. The data Fetch can acquire will not always be perfect.
Fetch is a tool that automatically acquires content given a URL. It contends with inconsistent (and errant) data but in most cases Fetch will save the seeder a lot of copy & paste effort.
When creating a new seed, click on the Fetch Seed button in the upper right hand corner, enter your URL and then edit the contents acquired by Fetch to suit your needs.
kudos, again, to the NT tech team!
I'm loving it!
This is partly a result of your image suggestion a while back. It sat on my to-do list because there were time-consuming technical hurdles getting images to work this way. But that always bugged me since your suggestion of directly fetching images from the web was spot on.
I'm honored to hear I had a tiny part of this. Thomas Edison said it was 10% inspiration and 90% perspiration.
Thanks for all the hard work
Keeping her busy again, are you?
It looks like you all did a lot of work to make this happen and I thank you
You are of course welcome Trout. Seeding was probably the biggest inconvenience left on NT. Although nobody will be able to tell, Fetch is the most complex single function on the site. With the COVID-19 lock down I had the ability to devote a steady stream of time to this endeavor. Given the nature of this beast, Fetch will continue to evolve.
He knows I'm game and always ready to tackle a challenge. And TiG knows how to create them.
He reminds me of my trigonometry teacher.
That's a compliment, BTW, I loved that guy. He was also our yearbook adviser and taught us how to play bridge when we put the yearbook to bed
Thanks TiG. I am always happy to assist whenever and wherever I can. Beta Testing is one of my favorite technical things to do. And I love the challenges. Fetch is really one of your best!
You da baby girl! Always up for a challenge.
Thank you for your kind words of support, Sister. I will never go down without a fight, thus, challenges of all kinds are my training grounds.
Raven is the best! She is dependable and careful. Truly a delight to work with!
Thanks Perrie. To some Beta testing can be frustrating. But, for me, it has always been fun, and I love a good challenge, and Beta testing does that. And TiG knows how to roll out the best challenges.
Looks and sounds good. I have spent a lot of time copying and pasting parts of articles as they are almost always divided with adds in between the text.
I don't have a twitter account and have never been able to copy or add tweets that were part of an article.
Fetch struggles with the advertisements (and other crap content) too. Sometimes the author / publisher inserts advertisement within the normal content and (I think purposely) gives no tell-tale clues that would allow a tool like Fetch to detect and exclude the ads. Fetch uses extensive algorithms to weed out bad content but it simply cannot catch everything. Ultimately, the seeder is still the final editor.
What I have noticed lately with the copy and paste, the font seems to be a bit larger than regular. One article I did ended up having two different font sizes.
I would have helped with the Beta yet I don't know what I am supposed to do. Haha
Perrie and I have noticed some odd things with the editor too. The editor is part of the underlying platform (a third party plug in at that) so we have very little influence over how it operates.
This Beta testing was a bit much to ask of members. Raven was a professional Beta tester so she has the experience to deal with something like this.
Thanks for all you do to improve the site, TiG. It is appreciated.
Absolutely! TiG's technical ability and knowledge to put together such great features and functions for NT and it's Members is truly a gift , and helps put NT one step above many other such sites on the Internet.
It is my very great honor and pleasure to work with him on his many developments, and I learn so much from the experience as well.
Well done TiG!

I usually blog because I find it easier - all I have to do is write. However, this seems to make seeding easier. I might try it.
the Fetch is a great function, yet, it has a few areas that may be in need of a bit of learning curve at first. But, the learning process is actually very simple, and once Members get the hang of what is needed on their part, which is minimal, it will make creating seeds much easier.
For the Members, as one of the Beta Testers on the Fetch, please feel free to ask for my assistance as well as TiG and Perrie, as one of us will likely be here at some point. And I am always happy to lend a hand in the learning process.
Thanks RW.
Your very welcome. Fetch is new to me as well, but, while Beta testing I learned a few things that can make it a bit easier to work with, and some workarounds that can save time during the process.
Oh, trust me, the first time I use it I will be running around crying HELP! I am so technologically challenged I can't even use my smart phone for anything more than calling and texting
This is fantastic, TiG.
With auto-import seeding (including the article image), NT now has all of the best functionality that I liked about Newsvine.
You've really done some amazing work here.
Let me pour you a fake beer.
Thanks, Dig.
Fetch will often leave editing work for the seeder. There is nothing (realistically) that can be done about that short of infusing world-knowledge AI that can understand semantics of conventional English (i.e. know the meaning of words and sentence structure to detect when an advertisement has been embedded within normal content). Although AI technology is getting better and more available without big $$$, that is a bit beyond what is currently possible on NT.
There is no doubt that I will continue to add techniques into Fetch's arsenal to improve its ability to detect bad content (while remaining general purpose).
That's okay. It seems like NV did too, if I remember correctly.
It's still super handy. The image fetch especially.
I tried an image rich article which I had to post the old fashioned way.
Fetch seed refused to work.
Fetch images said it worked but did not.
I just have to keep trying
Give me the url so that I can check it out.
By the way, if you are going after Bloomberg then you are out of luck. Bloomberg detects bots and denies them access to everything (images too). Fetch is, in effect, a bot and cannot help with Bloomberg seeds.
Fetch image probably got a URL from Bloomberg but when it tried to access its contents most likely was denied or discovered garbage. So Fetch Image will report it worked when it gets the URL, but will report failure when it tries to use it.
Welcome to my nightmare.
I do not remember much of NV's tool. I know it scanned for images and let you pick the one you wanted. I do not remember if it pulled in the actual content. The description (abstract summary) is often available in meta-data, but the actual content of the article is a very different animal. Do you remember how much NV pulled in? (I am curious.)
Tig,
It only pulled in the first 2 paragraphs. All images you had to fetch. So your dog fetches better than their dog did.
If NV was able to find the first two paragraphs of actual content then that is impressive. That, really, is much of the battle.
Nowadays the HTML is even more complex and thus finding the true content is not easy.
As you know, the standards exist to make this nice and clean but the authors and publishers (because this is what human beings do) like to roll their own standards. If everyone has their own standard, there is no standard. It is the Wild West.
Oh, I hear ya, and that is probably why NV gave it up. It was just too hard.
yep, Bloomberg.
Yeah, Bloomberg does not cooperate with bots. Fetch gets the door slammed in its face. With Bloomberg we will just have to copy & paste.
( And to think I was ready to support him for PotUS )
And NV, unlike NT, only allowed simple text (with minor formatting) in comments. No iFrames, embedded YouTube videos, images, gifs, etc. Lots of fun out there.
Well there I have to agree!
Like you, I remember it showed several images and gave you a choice.
I'm pretty sure it filled out the title for you, and added the source website's logo to the seed (if there was one).
I actually don't remember how much text was brought over. I don't think it was much, so there was still a bit for the seeder to do.
I agree with Perrie. Your dog fetches better. At least with the few articles I've played with so far. I didn't go ahead and post them, though. I was just doing test runs.
Given the way NV operated (pure cost-cutting mode), I would not be surprised if they stopped at the metadata. Each article has metadata (although even here there is a lot of competing standards). But, for the most part, one can almost always find the Title, Abstract and (less often) designated Image in the metadata. If one limits oneself to those three items, then the algorithm is pretty easy.
Author, believe it or not, is listed about ½ of the time. Thus Fetch must parse raw HTML to try to find a signature for a human name (with all the variations). So text like 'by George Q. Jetson' is of keen interest. But we cannot rely upon that since the author's name can manifest in many ways. And then, just to make things fun, the author name can be in many forms (and can even be a list of people in joint authorship):
The author finder algorithm within Fetch is pretty sophisticated, but it still can be fooled. Seeders need to verify the author is correct. One good thing is that sometimes the author is not visible to the seeder (is hidden) so Fetch can at times deliver info unavailable to the seeder.
Finally, the content itself is the uber nightmare. The vast majority of the HTML Fetch gets are processing instructions (code). And sometimes the HTML it gets is different than what is delivered to the Browser. And then worse, the Browser has all the tools to execute the instructions and produce content that Fetch never can see. Given the content it can acquire, Fetch has to sift through lots of non-content HTML and then navigate through teasers, advertisers, alternate articles, social links, etc. to try to find the content that the browser makes so obvious to the human user. And the standards that exist are often neglected or followed in creative ways; thus, in effect, no real standards exist. Fetch has all sorts of techniques in its arsenal to deal with this mess but it will definitely need human editing after the fact most of the time.
Given the content it can acquire, Fetch has to sift through lots of non-content HTML and then navigate through teasers, advertisers, alternate articles, social links, etc. to try to find the content that the browser makes so obvious to the human user. And the standards that exist are often neglected or followed in creative ways; thus, in effect, no real standards exist. Fetch has all sorts of techniques in its arsenal to deal with this mess but it will definitely need human editing after the fact most of the time.
If I can locate some free AI natural language technology that can help here, that will be the genesis of Fetch 2.0.
That will be something to really look forward to. Maybe at some point you can find a way to filter out the advertisements and unrelated images so that Fetch will ignore them and not pull the in during the Fetch.
Something we can look forward to maybe. While there is a lot of complications to over come, hopefully, we can manage to find a magic step to make that happen, or at least do a little more cleanup during the Fetch Seed process. We can hope anyway.
But, as the saying goes, where there is a will there is a way. And dreams can come true.
Making me thirsty bro!
One thing I would like to add regarding the seed and its image. In order for Fetch to create the seed it must have an image or the seed cannot be completed.
If the only image related to the seed is a slideshow, it cannot be added with the Fetch Seed, which would require the user finding a similar related image to use the Fetch Image function with, or, scroll through the slideshow and find an image they would like to use for the image.
Then the next steps would be needed:
Right click on the image and click on 'Copy Image location'
Once that is done, go back to the form and click on the Fetch Image button
When the URL bar appears, enter the URL for the location of the image you selected
Then update the form
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
The image should then be fetched and appear on the finished seed. I found this to be the most simple way to get around the slideshow issue, however, if the URL for the image is errant then Fetch cannot find it. But, that is a rare situation, and at some point, it may be something TiG may be able to resolve.
On my part, as I continue to work with the Fetch with TiG and be looking for workarounds for other areas that may present issues with author data or article creation that can simplify things with those issues.
TiG: If I have not explained this clear enough please add additional explanation to clarify and correct any confusion.
Your explanation is correct.
Basically, the Fetch Image button is available to acquire an image directly from the web. This saves us from having to download an image to our local machine and then upload it into our articles. So in those cases where the author did not designate an image for the article (or if the designated image is invalid, inaccessible, etc.) we always have the option of finding a suitable image and using Fetch Image to include it into our article based on its URL.
It is important that members realize that the main function Fetch Seed will always try to acquire the image designated by the author to represent the article. 9x% of the time Fetch is able to attach this image to the seed so the member will not have any work to do.
One of the misunderstandings about the Fetch is that I thought that you had to use both the Fetch Seed and Fetch Image to make it work properly and include the image. In working with you with the Fetch I found that it was not necessary to use both functions in the beginning, ONLY if there was no image with the article and Fetch Seed could not include, there was an error with the data that Fetch could not use, or there was a slideshow that Fetch could also not be fetched.
That is when I learned a few workarounds for using the Fetch Image function that will allow the seed to be completed. I think this is something that users should be aware of up front so that they will not be confused when using Fetch.
If I have given incorrect information, please correct it.
Tig is the best. He turned the drudgery of posting an article into a one-step breeze. Also, any additional changes a person may want can still be done. It is the best of both worlds!
None of you might get what a huge undertaking this was. The amount of exceptions out there on the internet makes a program like Fetch. What Tig did here was truly amazing!
I can't thank him enough.
Indeed it is. When I first started to Beta test Fetch I was not aware of all the complicated technology what was involved with creating it. The longer I tested Fetch the more I truly appreciated the depth of knowledge and technical expertise that is involved with trying to work with so many roadblocks involved with system, platform and author errors that simply could not be resolved. Kudos to TiG for a hard job well done.
Ok, just used it. It was quick and easy. Just put in the URL and hit fetch seed and it did all of it. Everything including author and seed pic.
Only had to edit out a few things.
Works great and was quick.
Thanks for the feedback Ender. Great news on your first try.
Great to know that you enjoyed using it.
It worked great.
My hat off to TiG.
Can you copy and paste the URL into FETCH?
That is the recommended way to operate. It is best to never type a URL, just copy it.
Yep That's what I did. Just copy and paste the URL and hit the fetch seed button. It retrieved all of it for me. It did get some extra like on the bottom of the article where it sometimes says more from then list other articles and those extra article ads in between text. I just backed those out.
The quickest seed I have posted.
Glad that it worked so well for you Ender. Whatever extra work the user needs to do after the seed is fetched only takes a couple of minutes compared to the copy/paste process from before.
Your, and others' findings and feedback affirms what we had hoped to achieve with this great function created by TiG, and attests to his technical abilities and inventiveness to help make NT a great forum for all.
Awesome TiG! Thanks! You da man!
Is this the surprise Perrie was talking about?
I think so.
Yeppers, Freewill. See it was worth the time.
This is great ! Thanks, TiG !
Great work.